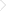1、多量量操作js作弊的网站被降权甚至被k
巨匠都知道,百度对淘宝的工具是相当敏感的,是以淘宝客的网站是一类操作js隐瞒蜘蛛爬行的典型网站,然而自年夜百度6-28(6月28日多量量网站被k)事务起头,淘宝客类型的网站当然是受到了重创,不少以返利为盈利的淘宝客站长收入一度下降,就这一类型的网站底是不是因为百度手艺进级而识别了js琅缦沔的淘宝链接呢?
相信良多站长如不美观网站收录不正常或者是长时刻没有被百度收录的话都用试用各类工具去剖析网站,本人新站不收录,便当用站长统计工具剖析网站的seo情形,不剖析不知道,一剖析吓一跳,百度站长统计琅缦沔的网站诊断既然能剖析出js琅缦沔的链接,既然这里能识别出js代码琅缦沔的链接,相信蜘蛛也能识别js代码的链接。
2、新站设计js作弊的网站一律不收录


综上所述,即即是知名国外GOOGLE也未能完全识别JS代码,可是相关的例子音及事实证实百度对JS至少有了初步的识别功能,至于能识别到什么水平,但愿阅读本文的志同志合人士进一步具体剖析给出更有说服力的例子。
本人新做一个淘宝客的网站仍是担任以前的模式,淘宝链接用js代码潜匿起来,可是过了十天、半个月,到此刻已经一个月曩昔了百度就是不收录,蜘蛛天天城市来爬,就是不给收录,而且还会爬行js。当然这也正常,可是当体味到良多想再以这种模式爬起来的淘宝客站长也是跟这种情形,不得不让人起头思疑百度蜘蛛已经起头读懂js代码了。
文章来历:www.doota.com,转载请标明。
3、操作百度统计剖析网站时可以剖析出js代码里的链接
比来剖析网站日志,发现一个奇异的现象,百度蜘蛛起头爬行网站里的js文件了,而且几乎天天都来爬行,这个现象也获得良多站长伴侣的证实。就百度蜘蛛爬行js文件到底能不能完全识别js代码里的链接以及文字特作了以下剖析:
(这些链接都是用挪用js代码的在百度统计琅缦沔完万能剖析出来)
注:相关网站培植技巧阅读请移步到建站教程频道。
 粤公网安备44010502000280号
粤公网安备44010502000280号 公众号二维码
公众号二维码
 小程序二维码
小程序二维码